Code for this tutorial can be found on Github
Introduction
Web scraping is a useful tool for extracting data from websites, especially those that don’t provide an API. In this post, I’ll show you how you can use web scraping to generate a dataset from a webpage.
For this example we will be using a website called trendogate which is a website that displays trending twitter hashtags on a given day based on region. Our goal will be to retrieve hashtags that are currently trending in the US.
To do this we will primarily be using two libraries:
1. Urllib
Urllib is a Python module that can be used for opening URLs. It defines functions and classes to help in URL actions. With Python you can also access and retrieve data from the internet like XML, HTML, JSON, etc.
Urllib is going to help us retrieve the web page we want to scrape.
To install Urllib-
pip install urllib
2. Beautiful Soup
Beautiful Soup is a Python package for parsing HTML and XML documents. It creates a parse tree for parsed pages that can be used to extract data from HTML, which is useful for web scraping
Once we have the page we need from Urllib, we’re going to use Beautiful Soup to create a parse tree and extract the information we need from the page.
To install Beautiful Soup
pip install BeautifulSoup4
Analysing the web page
To scrape a webpage you need to be familiar with the structure of the HTML tags in that page. So right click on the page you want to scrape and select Inspect.
The trendogate webpage looks like this:
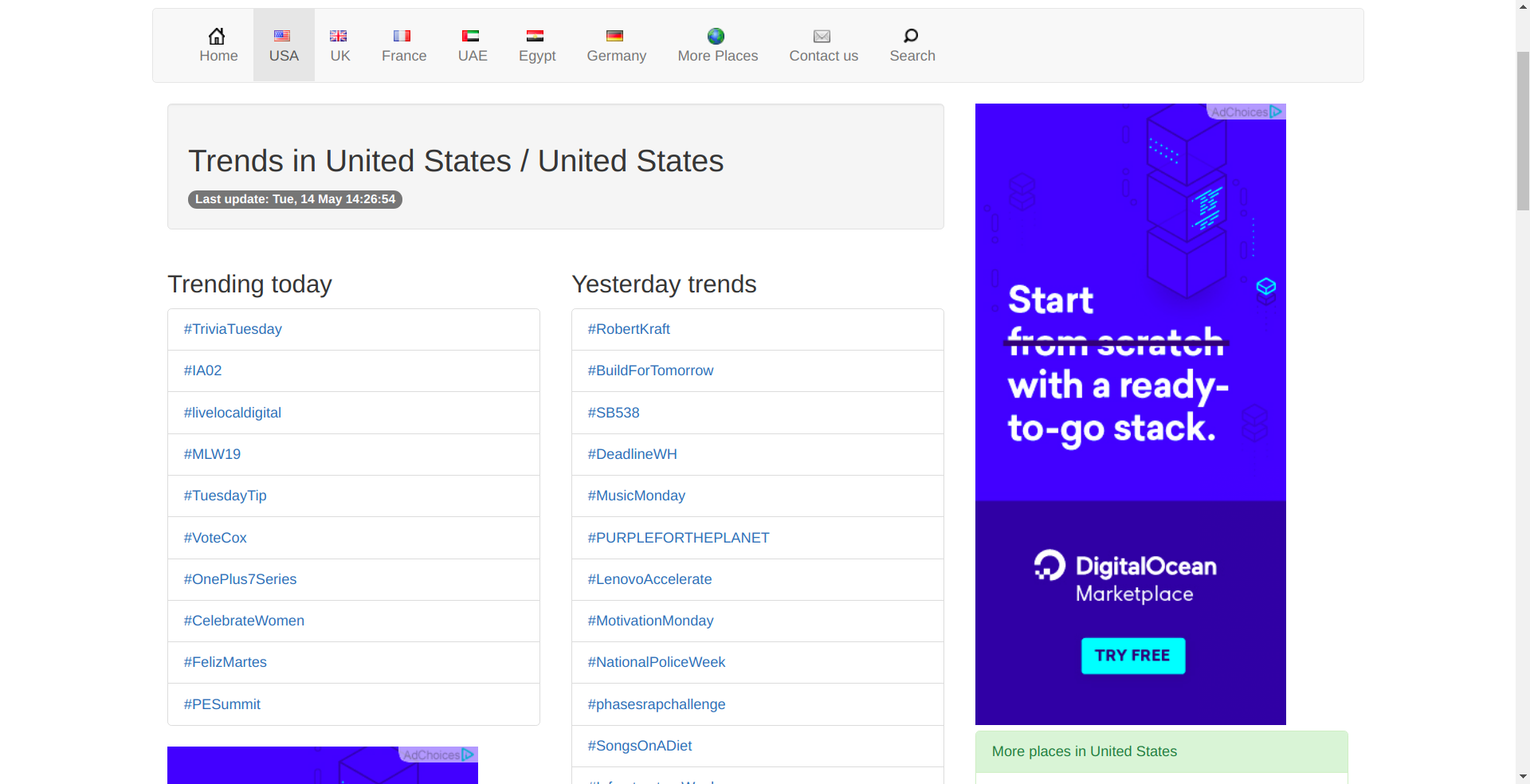
We are interested in the trending today section. If we inspect it we can see the HTML structure.
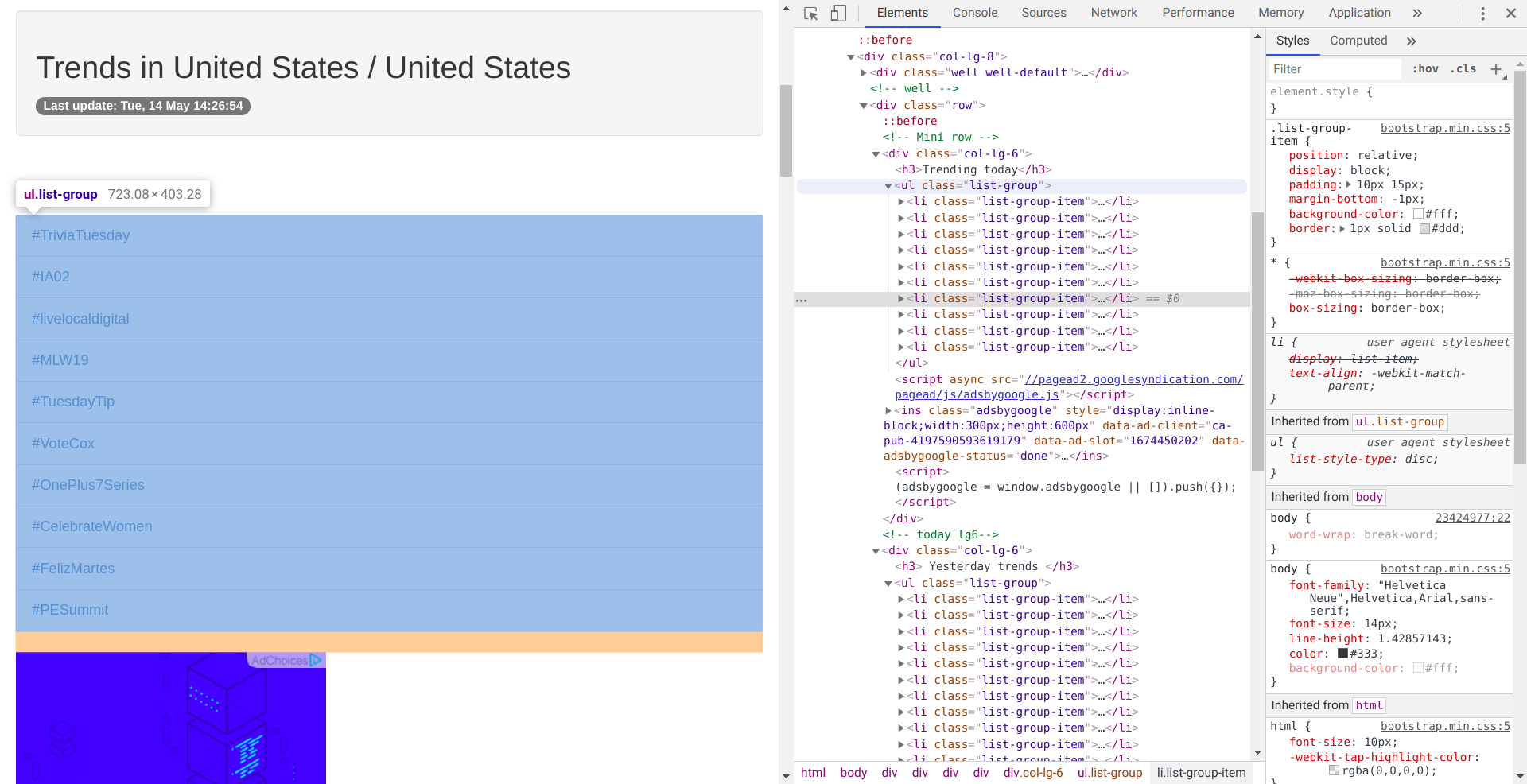
Today’s trending hashtags are in an unordered list of class list-group that looks something like this:
<ul class="list-group">
<li class="list-group-item"><a href="/trend/79334795"> #TriviaTuesday</a></li>
<li class="list-group-item"><a href="/trend/79334794"> #IA02</a></li>
<li class="list-group-item"><a href="/trend/79334793"> #livelocaldigital</a></li>
<li class="list-group-item"><a href="/trend/79334792"> #MLW19</a></li>
<li class="list-group-item"><a href="/trend/79334791"> #TuesdayTip</a></li>
<li class="list-group-item"><a href="/trend/79334790"> #VoteCox</a></li>
<li class="list-group-item"><a href="/trend/79334789"> #OnePlus7Series</a></li>
<li class="list-group-item"><a href="/trend/79334788"> #CelebrateWomen</a></li>
<li class="list-group-item"><a href="/trend/79334787"> #FelizMartes</a></li>
<li class="list-group-item"><a href="/trend/79334786"> #PESummit</a></li>
</ul>First we import the libraries we’ll need
from bs4 import BeautifulSoup
import urllibThen we’ll use urllib to get the webpage. Read more about urllib
URL = "https://trendogate.com/place/23424977"
# Open the URL
page = urllib.request.Request(URL)
result = urllib.request.urlopen(page)
# Store the HTML page in a variable
resulttext = result.read()Now we’ll create a BeautifulSoup object from the HTML page we just retrieved. Read more about BeautifulSoup
# Creates a nested data structure
soup = BeautifulSoup(resulttext, 'html.parser')
# Since we are interested only in an element with class "list-group"
# We will search for all elements with that class in the soup
soup = soup.find_all(class_= "list-group")
# Soup now contains an array of all elements with the class "list-group"
# Since the Trending today list is the first on the page, it's index is 0
trending_list = soup[0]
# Now we will iterate through the elements of the <ul>
# <ul> has <li> tags nested inside
trending_tags = []
for li in trending_list.contents:
# There is an <a> tag nested in each <li>
a = li.contents[0]
# The contents of 'a' is just the text inside the tag
tag = a.contents[0].strip()
trending_tags.append(tag)
print(trending_tags)Now we have scraped all of today’s trending hashtags from the website